
View
* HDFS Erasure coding (Hadoop 3.0.0-alpha1, HDFS-7285)
1. 개요
1) HDFS의 storage 및 network overhead를 줄이기 위해서 고안됨
2) 3-replica 는 데이터 블록의 중복으로 인해 200%의 storage space overhead를 가지나, EC(Erasure Coding) 방식은 데이터 블록의 절반의 패리티parity 블록을 위한 50%의 overhead를 가짐

그림1 - Erasure coding의 storage efficeincy : https://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
3) EC는 HDFS replica와 동일한 수준의 fault tolerance 제공
4) EC를 사용하는 경우 Data block 을 3-replica로 유지하기 위해 사용되는 network bandwidth가 없어짐
5) 3-replica에 비해 encode/decode로 인해 CPU 부하가 늘어날 수 있음. (Intel ISA-L coder와 같이 CPU에서 EC를 지원하기도 함)
2. Erasure Coding 동작 방식
1) Reed-Solomon Algorithm, XOR 방식 등을 사용
2) RS(6,3)은 6개의 데이터 블록과 3개의 패리티 블록을 갖는 것을 의미하며, 3개의 데이터노드 failures를 견딜 수 있음
3) RS(10,4)는 10개의 데이터 블록과 4개의 패리티 블록을 갖는 것을 의미하며, 4개의 데이터노드 failure를 견딜 수 있음
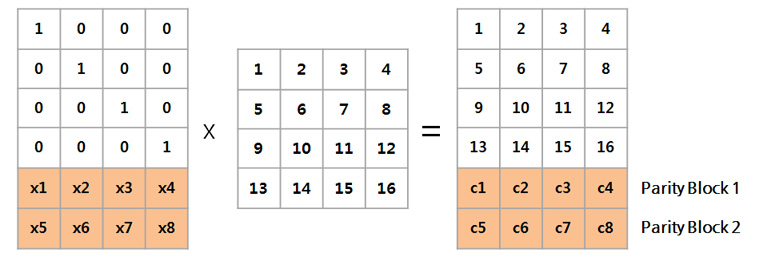
그림2 - Erasure coding의 blcok 구성: https://www.samsungsds.com/global/ko/support/insights/Hadoop3-coding.html
4) 손실된 block 들은 남아있는 block들을 이용하여 재구성 할 수 있음.
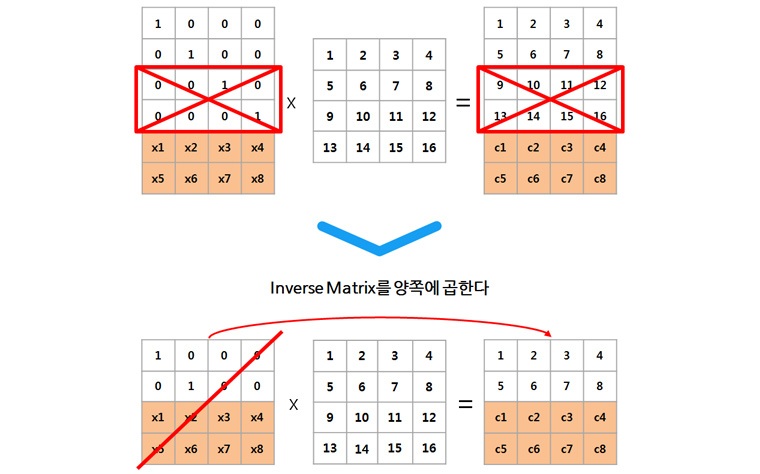
그림3 - RS 기반의 복구방법 : https://www.samsungsds.com/global/ko/support/insights/Hadoop3-coding.html
5) EC policy에 따라 작은 데이터를 저장하는 경우 패리티 블록으로 인한 storage overhead가 replica 보다 더 커질 수 있음. (striped layout 적용과 EC policy 설정 최적화가 필요하다. HDFS-7285)
3. 적용 사례 및 기타
1) Hive 등의 Archive storage로 사용 - 다시 사용할 일이 없으나 삭제할 수 없는 별도의 데이터를 EC zone으로 설정하여 저장.
2) Hadoop 클러스터의 DR(Disaster-Recovery) 시스템으로 사용.

그림4 - EC 사용 사례: https://ko.hortonworks.com/blog/data-lake-3-0-part-4-cutting-storage-overhead-in-half-with-hdfs-erasure-coding/
3) 기존 data를 EC 방식으로 전환하는 것은 계획 중
4) Hive나 HBase와 같이 HDFS 기반의 서비스에 대한 성능 검증은 아직 이루어지지 않음.
5) 패리티 계산을 위해 client 가 수 GB의 버퍼가 필요할 수 있음으로 배치 작업이나 오프라인 작업을 통해 EC가 적용 되어야 함.
참조 :
EC bentchhttps://issues.apache.org/jira/secure/attachment/12690129/fsimage-analysis-20150105.pdf
https://blog.cloudera.com/blog/2015/09/introduction-to-hdfs-erasure-coding-in-apache-hadoop/
https://ko.hortonworks.com/blog/data-lake-3-0-part-4-cutting-storage-overhead-in-half-with-hdfs-erasure-coding/
https://www.samsungsds.com/global/ko/support/insights/Hadoop3-coding.html
'02.IT공부(간헐적취미) > 빅데이터' 카테고리의 다른 글
| [zookeeper] 과반수 구성 이유 (majority voting/quorums) (0) | 2019.02.09 |
|---|---|
| [HDFS] TestDFSIO : Benchmark tools on hadoop cluster -하둡 클러스터 성능분석 도구(1) (0) | 2018.12.06 |
| [BIGDATA] hadoop과 Object storage (0) | 2018.11.22 |
| [HDFS] Hadoop HDFS balancer수행 및 bandwidth변경 (0) | 2018.10.10 |
| [Hive] 파티션 종류 및 특징 (0) | 2018.08.28 |
