
View
최근 몇 년간 다양한 cloud 서비스가 개발/확산으로
WEB, WAS, Storage 심지어 ERP까지 AWS, Azure, Google cloud와 같은 public cloud 서비스를 이관하고 있다.
Public cloud 서비스의 가장 큰 장점은 확장성과 비용이기 때문에
많은 데이터를 저장해야 하고 다수의 node가 필요한 hadoop cluster를 구축하기 좋은 선택이다.
그리고 같은 이유로 block storage(HDFS)를 사용하는 대신 object storage를 사용하기 시작했다.
* * *
Bigdata 시스템에서 왜 object storage를 사용할까?
1. HDFS capacity overhead를 줄여준다.
HDFS는 fault tolerance를 보장하기 위해서 데이터블록을 3-replica를 유지한다.
반면에 위에서 설명한 것과 같이 object storage는
object level에서 erasure encoding를 사용하여 동일하게 fault tolerance를 보장한다.
그렇기 때문에 HDFS의 3-replica 로 인한 storage space overhead 가 줄어든다.
2. object storage는 master node가 갖는 single point of failure 를 제거한다.
HDFS는 한개의 마스터 노드(active namenode)와 다수의 슬레이브 노드(data node)를 가지고 있다.
Namenode가 data block에 대한 다수의 metadata 정보를 가지고 있기 때문에
datanode는 namenode 주기적으로 자신의 데이터블록에 대한 정보를 namenode로 전달하고,
replication에 대한 결과를 전달 받는데 namenode에 문제가 발생하는 경우
클러스터 전체에서 데이터에 대한 접근을 할 수 없게 된다.
이를 위해 HDFS는 standby namenode를 통해 fsimage 및 edits를 복제함으로써
이러한 이슈 상황에 대한 HA를 제공한다.

HDFS HA architecture : https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability/
Object stoage는 HDFS와 같이 master node가 별도로 구분되어 있지 않다.
metadata는 object storage 어디든 옮겨질 수 있다.
그렇기 때문에 master node가 실패하더라도 slave node는 빠르게 master node가 될 수 있다.
object storage 는 별도의 spare drive를 가지고 있어
예기치않은 drive failure에 대해서도 erasure encoding을 통해 자동으로 복구할 수 있다.
3. Object storage은 operation 리소스와 storage 리소스를 독립적으로 확장할 수 있다.
HDFS를 사용하는 경우 일반적으로 data locality를 활용하기 위해
하나의 host 위에 hdfs datanode와 yarn node manager를 같이 설치한다.
더 많은 node manager를 사용하기 위해 장비를 도입하려면
불필요하게 storage 리소스도 함께 확장해야 한다.
반면에 object storage 기반으로 cluster 를 구성한 경우
storage 리소스는 object storage 에서 관리되기 때문에
operation / storage 리소스를 독립적으로 확장 할 수 있다.

그림 - hadoop connections for object storage : https://www.ibm.com/blogs/cloud-computing/
이렇게 좋은 장점에도 불구하고 실제 프로젝트에서는
고성능이 필요한 빅데이터 플랫폼에서 object storage를 사용하는 것을 크게 권장하지 않는 분위기이다.
* * *
많은 장점에도 불구하고 object storage를 사용하지 않고 왜 HDFS를 사용할까?
1. N/W 대역폭을 많이 사용하는 서비스 모델인 경우
hadoop에서도 object storage 사용을 위해 apache ozone을 개발중이지만
현재 대부분의 object storage는 cloud 서비스로 제공된다.
그렇기 때문에 데이터 접근을 위해서는 N/W 가용성이 매우 중요하다.
프리미엄 서비스가 아닌 일반적인 object storage의 경우
N/W 대역폭이 높지 않다.
이런 이유로 아이러니 하게도 대량의 데이터를 빠르게 처리하기에 적합하지 않다.
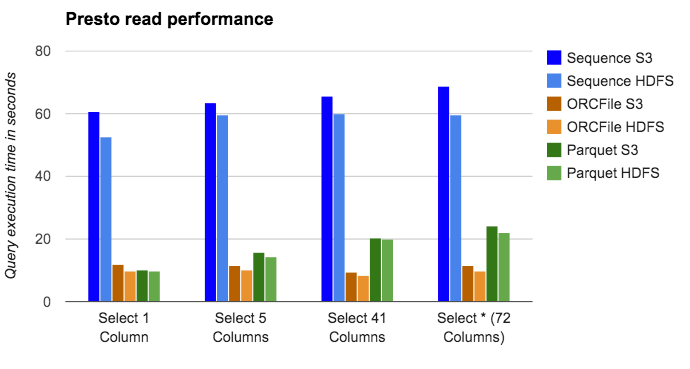
그림 - performance HDFS vs S3 : https://medium.com/netflix-techblog/using-presto-in-our-big-data-platform-on-aws-938035909fd4
(실제로 Hive LLAP에서 query를 수행 하였을 때 위 결과보다 더 크게 성능차이가 났다.)
데이터를 인터렉티브Interactive하게 읽어서 데이터 처리해야 하는 경우나
용량이 큰 데이터들의 집합을 이용하여 분석작업을 수행하는 경우에는 적합하지 않다.
(물론 수행 속도에 대한 SLA가 없다면 불가능하진 않다)
이러한 문제는 N/W 병목으로 인한 것 이기 때문에 worker 노드를 증설해도
수행 속도가 크게 빨라지지 않는다.
위에서 언급한 작업들의 경우
HDFS의 장점인 data locality를 활용하여 낮은 비용으로 데리터 처리를 해야 한다.
일부 vendor들은 HDFS 와 오브젝트 기술들의 장점을 모아
object 시스템을 만들어 mapreduce 기능을 storage system 안에서 수행하기도 한다.
하지만 이것은 하둡 호환성을 넘어선 고성능의 storage가 필요하게 됨으로 범용성이 떨어진다.
결론적으로..
Object storage는 비구조화된 데이터 이면서 읽기작업이 대부분인 데이터에 대해서 잘 동작한다. (웹 컨텐츠, 데이터 백업, 아카이브 이미지, 비디오, 그림, 음악 등)
Cloud 기반 object storage는 N/W 대역폭의 제한이 있음으로 대량의 데이터를 빠르게 처리하는데 한계가 있음으로 cloud block storage / local hdfs 를 사용하는 것이 좋다.
다만 hadoop 에서 지속적으로 object storage 동작들의 최적화 작업이 지속적으로 이루어 지고 있기 때문에 지금보다 더 좋은 성능을 기대할 수 있을 것이라는 것은 확실하다.
가장 중요하고 당연한 것은 각 프로젝트의 비즈니스 요건에 맞춰 PoC를 진행한 후에 그 결과에 따라 HDFS / Object storage를 결정하는 것이다.
참고자료들
https://www.youtube.com/watch?time_continue=68&v=7sOOBpprSO0
https://www.datanami.com/2015/06/23/data-lake-showdown-object-store-or-hdfs/
https://it.toolbox.com/blogs/maryannrichardson/3-reasons-to-replace-hdfs-with-object-storage-and-1-reason-not-to-103117
https://cdn.oreillystatic.com/en/assets/1/event/228/Hadoop%20and%20object%20stores_%20Can%20we%20do%20it%20better_%20Presentation.pdf
'02.IT공부(간헐적취미) > 빅데이터' 카테고리의 다른 글
| [HDFS] TestDFSIO : Benchmark tools on hadoop cluster -하둡 클러스터 성능분석 도구(1) (0) | 2018.12.06 |
|---|---|
| [HDFS] Hadoop 3.x new feature : Erasure coding (2) | 2018.11.22 |
| [HDFS] Hadoop HDFS balancer수행 및 bandwidth변경 (0) | 2018.10.10 |
| [Hive] 파티션 종류 및 특징 (0) | 2018.08.28 |
| [Hive] Hive LLAP 메모리 설정 가이드 (0) | 2018.08.21 |
