
View
Apache ozone 벤치마킹 자료 (by cloudera)
다양한 산업군의 기업들이 데이터 분석을 통한 높은 수준의 비즈니스 서비스를 제공하기 위해
가지고 있는 모든 데이터를 하나의 저장소에 모으려는 노력을 하고 있다.
(+ 물론 아직까지 남들이 하니까 일단 모으고 보자는 곳들도 존재한다 ~ ___ ~)
일반적으로 주위에서 데이터의 양과 일상적으로 처리해야 할 데이터가 많지 않은 기업들은 CSP의 서비스를 사용하고 있으며, 데이터가 많으며 지속적인 처리작업이 이루어지거나 개인정보 및 국가에서 관리하는 기술 민감정보를 가지고 있는 기업들은 on-premise에 자체적인 data lake를 구축하는 추세이다.
이때 쉽게 그리고 싸게 생각할 수 있는 것이 범용장비 여러대로 구성할 수 있는 하둡 기반의 Data lake 일 것이다. 하둡은 오픈소스 기반이면서 범용적으로 사용하고 이미 전 세계적으로 검증된 아키텍쳐이기 때문에 큰 어려움 없이 도입할 수 있다. 하지만 아래 글과 같이 크기가 작은 파일들을 다수 저장할 때에는 HDFS(Hadoop distribuded File System)의 구조적 한계에 부딪치게 된다.(약 3억5천만개의 파일까지 저장할 수 있다)
이러한 문제로 다수의 하둡 클러스터를 복수개로 구성 (Hadoop federation)할 수 있긴 하지만 관리적인 어려움이 발생하기 때문에 이를 극복하기 위해 object storage 아키텍쳐를 채택한 ozone이라는 프로젝트가 tech preview 상태로 개발중이고 빠른 속도로 진행중이다. 또한 apache ozone을 사용하게 되면 storage 자원과 compute 자원을 나누어 구성할 수 있기 때문에 클라우드 환경(아마도 private cloud)에서 작업 부하에 따라 동적으로 노드 관리를 할 수 있다.
이러한 상황에서 하둡 배포판을 제공하는 세계적인 벤더인 cloudera에서 apache ozone을 기존 HDFS와 비교의 벤치마크 테스트를 진행했기에 그 내용을 짧게 보았다. 테스트의 과정은 매우 험난했을 것으로 보이나(계획, 구성 그리고 최적화가지..) 결과는 생각보다 간단하다. 본문은 아래와 같다
- Apache Hadoop Ozone은 HDFS의 주소체계의 확장성 한계를 극복하기 위해서 고안되었다.
HDFS 같은 경우 작은 파일들이 많이 존재하는 경우 그 파일들을 관리 하기 파일 시스템 오브젝트(meta data, inode 등) 이 비효율적으로 많아짐으로 비효율적이다.
- 지금 기술로 제공되는 하드웨어로 구성된 하둡 클러스터 같은 경우 HDFS는 약 350,000,000 개 정도의 파일과 700,000,000 개의 파일시스템 오브젝트까지 저장할 수 있다.
Ozone의 아키텍쳐는 이러한 제한을 해결하기위해 구상되었다. 이 글은 사실상 HDSF와 Ozone의 아키텍처의 차이에 대해서 이야기 하려는 것이 아닌 성능차이에 대해서 기술한다
- 성능 차이를 확인하기 위해 널리 사용되는 벤치마크 도구인 TPC-DS를 사용한다. 이 도구는 일반적으로 Hadoop 스택(Hive, Tez, Yarn 그리고 Ozone과 비교가 될 HDFS)에서 성능 측정을 위해 사용된다.
현재 많은 산업군에서 compute 자원과 storage 자원을 분리해야 하는 요구사항들이 많이 나오는데 이것은 storage는 상대적으로 고정적이고 compute 자원은 유연하게 사용되기 때문이다.
그렇기 때문에 이 테스트에서는 HDFS datanode의 노드와 Yarn의 NodeManager의 노드를 분리시킨체로 테스트를 진행하였다.
- 이런 노력의 근본적인 목적과 제품 최적화에 대한 추가적인 노력을 통해서 HDFS의 안정성 및 성능 최적화와 비교할 수 있어야 할 것이다.
이것을 위해서 몇 개월동안 커뮤니티에서 수행한 작업들을 제공하려 한다. 현재 CDP에서 ozone은 beta버전으로 릴리즈될 예정이다.
테스트 수행 내역 (Ozone 기반의 hive의 성능이 빠르게 수행됨)
- 아래의 측정값들은 두개의 독립된 데이터셋인 100GB, 1TB에서 수행된 결과로 12개의 지정된 storage와 별도로 구분된 12 개의 compute 노드에서 수행된다. (이 글의 마지막 부분에서 설정 값에 대한 더 상세한 결과를 제공할 예정이다)
- 아래 그림은 전체 99개의 테스트 벤치마크 쿼리의 총 수행시간을 나타내는데, Ozone이 약 3.5% 차이로 두 데이터셋에서 더 좋은 결과를 얻었다.

TPC-DS 쿼리 1번부터 99번까지 수행한 총 시간을 나타낸 것으로 1시간이 좀 안되게 걸린 것으로 보인다.
조금씩 차이가 나는 것은 외부 요인이라고 생각되며 100GB는 큰 차이가 없는 것으로 보인다.

100GB에 비해서 조금 더 비율적으로 많이 차이가 나는 것으로 보인다. 1TB 데이터셋에 대해서 100GB보다 약 3배의 실행 시간이 증가되었다. 마찬가지로 외부요인에 의해서 차이도 달라지는 것으로 보인다.
- 더 자세한 결과를 얻기 위해서 쿼리를 3가지 분류로 구분하였다.
a. Ozone에서 더 빠른 쿼리들
b. HDFS에서 더 빠른 쿼리들(차이 25% 이하)
c. HDFS에서 더 빠른 쿼리들(차이 25% 이상)

대부분의 쿼리가 ozone에서 빠른 결과 값을 얻었다. 2개의 쿼리가 ozone에서 매우 느린 성능 결과를 얻었는데
쿼리의 수행 작업에 따른 분류로 구분을 해주거나 outliers가 어떤 쿼리인지 확인할 수 있으면 더 좋았을텐데 아쉬움이 남는다.

100GB에서 1TB로 데이터가 증가하자 faster가 줄어들고 outlier가 1개 증가하였다. 어떠한 쿼리인지 모르는게 정말 아쉽다.
- 70% 케이스 이상에서 Ozone이 HDFS 보다 더 좋은 성능을 가지고 있다는 것을 나타낸다.
커뮤니티에서 더 안정화 하고 높은 성능을 위해서 노력했지만 이 이상의 성능을 낼 수는 없었다.
- 아래에서는 TPC-DS 쿼리 각각의 성능 차이를 정리한 것이다. 이러한 결과는 연속된 10번의 수행 결과의 평균 값을 노즈값을 제외하고 표준화 한 것이다.
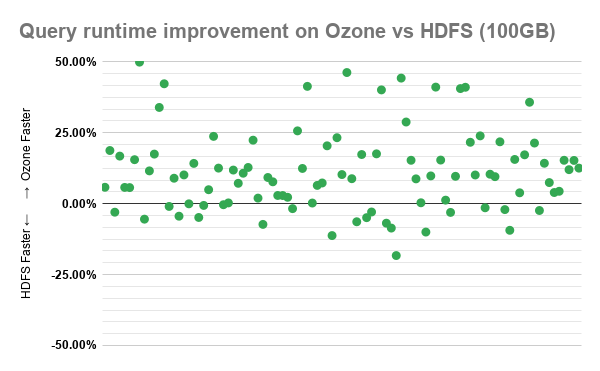
특정 쿼리에서 50% 정도의 실행시간 차이가 있다는 것은 매우 유의미한 결과가 아닌가 싶다.

100GB에 비해서 1TB로 데이터셋이 증가하면서 전체적으로 점들이 HDFS faster 쪽으로 내려왔다. 데이터의 양이 많으면 많을 수록 HDFS가 좋은 성능을 가질 것이라고 예측할 수 있을 것 같다.
결론
- TPC-DS 테스트의 결과로 70% 이상의 쿼리에서 약간 씩 더 빠른 성능을 갖는 것을 알 수 있었다.
여기에는 몇가지 이상치(outliers)들이 발생하였는 이는 병목현상 및 우선순위 문제로 발생한 것들이었다.
- Ozone은 tech preview 상태로 CDP-DC 에서 릴리즈 되었고 지속적인 피드백을 통해서 차세대 빅데이터 분산 스토리지 시스템을 발전시키고 있다. 이전에 언급했던 것처럼 beta release 가 매우 빨리되어야 되며, GA가 빠르게 뒤따라야 할 것이다. 이번 테스트와 같은 결과들이 안정성 및 성능 측면에서 빠른 GA를 현실적으로 만들어 줄 것이다.
테스트 환경
- 28개의 동일한 물리 노드
. 20 core intel Xeon CPU
. 128 GB memory
. 4*2TB 디스크
. 10Gb/s 네트워크
- Centos 7.4
- Cloudera Runtime 7.0.3 (Hadoop3, Hive3, Tez 0.9, 2020년 2월 git master에서 빌드된 버전의 Ozone)
. 4개의 master node (CM, Prometheus, Zookeeper, Yarn, Hive, HDFS, Ozone master)
. 12개의 storage node / 12개의 compute node (3개의 노드가 yarn log로 할당됨)
. SSL/TLS 는 비활성화 되어 있으며, simple authentication이 사용됨
. ozone은 하나의 버켓을 가진 volume을 사용함으로써 HDFS와 유사하게 구성함
. 어떠한 서비스도 HA는 설정하지 않음
- 클러스터의 인터넷 네트워크는 다른 노드들과 공유하여 트래픽이 전체적으로 높았다 낮아졌다 할 수 있음
(그렇기 때문에 10번의 테스트의 결과의 평균값을 구함)
- Hive의 결과 캐쉬 저장(LLAP?)는 비활성화 시킴으로써 모든 데이터는 FileSystem에서 읽어 올 수 있도록 함
- TPC-DS는 다음 repo에서 받아옴(https://github.com/hortonworks/hive-testbench)
전체적으로 Ozone이 HDFS보다 전반적으로 높은 성능을 얻었다는 점에서 유의미한 결과를 얻은 테스트라고 생각한다. 하지만 이 테스트 결과 아티클에서 갖는 아쉬움은 몇가지가 존재한다.
> 첫번째로 어떠한 ozone에서 어떠한 최적화 작업이 이루어졌는지와 HDFS에서 동등한 최적화 작업이 이루어졌는지에 대한 것이다.
> 두번째는 어떠한 쿼리를 수행하였을때 HDFS에서 좋은 성능이 나왔는지, 어떤 쿼리가 ozone에서 성능이 좋아졌는지에 대한 내용이 없다는 것이다.
> 마지막은 만약 storage와 compute 노드가 동일한 노드로 구성되었을때의 성능이 같이 제공되었다면 테스트가 더 완벽했을 것이라고 생각한다. 비록 테스트에 앞서 storage와 compute 노드를 분리하고자 하는 요구사항이 높아진다고 하지만 HDFS 자체가 compute 자원과 storage 자원을 동일한 노드에 구성하도록 설계가 되었기 때문에 ozone이 구성된 노드에 node manager가 같이 있다면 어느정도 성능 향상이 발생하는지도 제시가 되었다면, 각 환경에 맞는 최적화된 아키텍쳐를 설계할 수 있기 때문이다.
결과적으로 매우 재미있고 의미있는 벤치마크 테스트였다. 생각 했던 것 보다 apache ozone이 더 빠르게 GA될 수 있다는 생각과 함께 아직은 도입을 고민해야 할 시기가 아니라는 확신이 들게 되었다.
출처 : https://blog.cloudera.com/benchmarking-ozone-clouderas-next-generation-storage-for-cdp/
'02.IT공부(간헐적취미) > 빅데이터' 카테고리의 다른 글
| [NiFi] FlowFile 이란? - 어떻게 memory/disk 에서 처리되는가? (3) | 2020.10.11 |
|---|---|
| [NiFi] NiFi는 어떻게 데이터를 저장하나? (NiFi Repository) (1) | 2020.10.07 |
| [빅데이터]HDFS와 Cloud Storage 비교 & 장단점 (1) | 2019.08.04 |
| [zookeeper] 과반수 구성 이유 (majority voting/quorums) (0) | 2019.02.09 |
| [HDFS] TestDFSIO : Benchmark tools on hadoop cluster -하둡 클러스터 성능분석 도구(1) (0) | 2018.12.06 |
